라즈베리파이 os 설치하기
raspberrypi imager를 통해 라즈베리파이의 os를 깔아줍니다. 해당 프로그램은 링크에서 자신의 컴퓨터 os에 맞게 설치할 수 있습니다. 설치 후 sd카드를 꽂으면 이미저에서 sd 카드를 인식하고 아래 사진처럼 옵션을 선택하여 라즈베리파이 os를 설치할 수 있습니다.
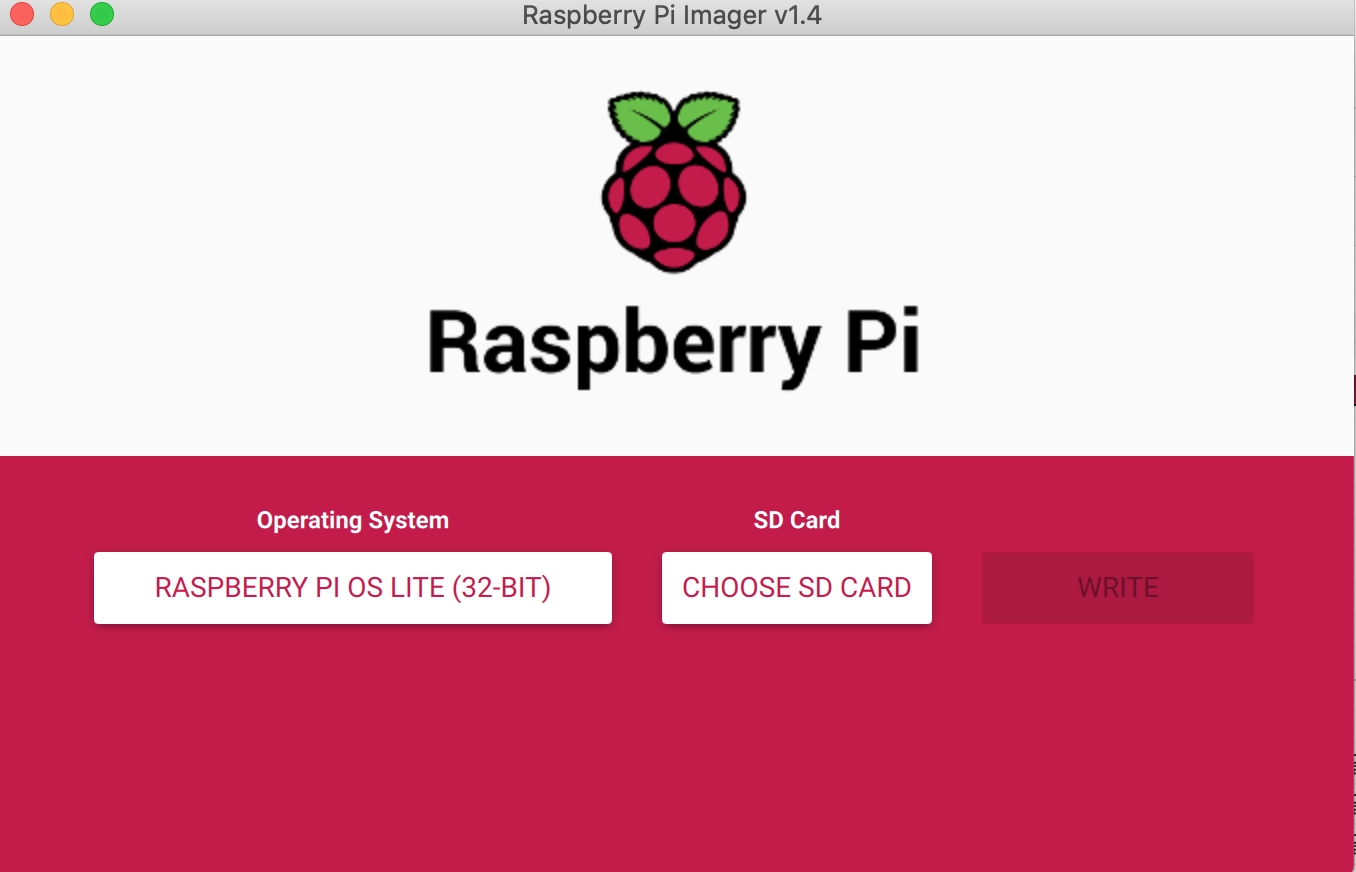
설치가 종료된후 sd 카드가 자동으로 언마운트 되므로 다시 삽입 해주신 후 터미널이나 cmd를 열고 아래와 같이 치고 sd카드를 뺀 후 라즈베리파이에 장착해 줍니다. 같은 과정을 모든 라즈베리파이 수 만큼 반복해줍니다. 이 작업은 라즈베리 파이 ssh를 활성화 해주기 위함입니다.
1
2
3
|
cd /Volumes/boot
touch ssh
cd
|
라즈베리파이 간 서로 연동하기
아래의 코드는 자신이 가진 모든 라즈베리파이에서 실행하는 코드입니다.
먼저 아래 명령어로 라즈베리파이에 ssh로 접속해줍니다. ssh-keygen 을 통해 호스트의 권한을 새로 만듭니다. ssh를 통해 접속을 하게 되면 비밀번호를 치라고 하는데 초기 비밀번호는 raspberry 입니다. 저는 비밀번호를 변경하지 않고 진행할 예정이니 외워두는게 좋습니다. 참고로 보안을 위해서 각 라즈베리파이의 비밀번호를 수정해주어야 합니다.
1
2
|
ssh-keygen -R raspberrypi.local
ssh pi@raspberrypi.local
|
이후 아래 코드로 라즈베리파이의 업데이트와 업그레이드를 해줍니다. 업그레이드 과정에서 시간이 좀 소요될 수 있습니다.
1
2
|
sudo apt-get update
sudo apt-get upgrade -y
|
아래의 명령어로 설정에 들어가고 시스템 옵션 Hostname 칸을 눌러 사용자 이름을 변경할 수 있습니다. 저는 3개의 라즈베리 파이가 있고 그 중 하나를 마스터로 사용하고 나머지 둘을 워커로 사용할 것입니다. 따라서 마스터로 사용할 라즈베리파이의 이름을 master로 변경해줍니다. 워커가 될 라즈베리파이의 이름은 worker1, worker2로 설정합니다. 이름을 재설정하면 자동으로 리부팅 됩니다. 이름을 재설정하는 이유는 모든 라즈베리파이의 초기
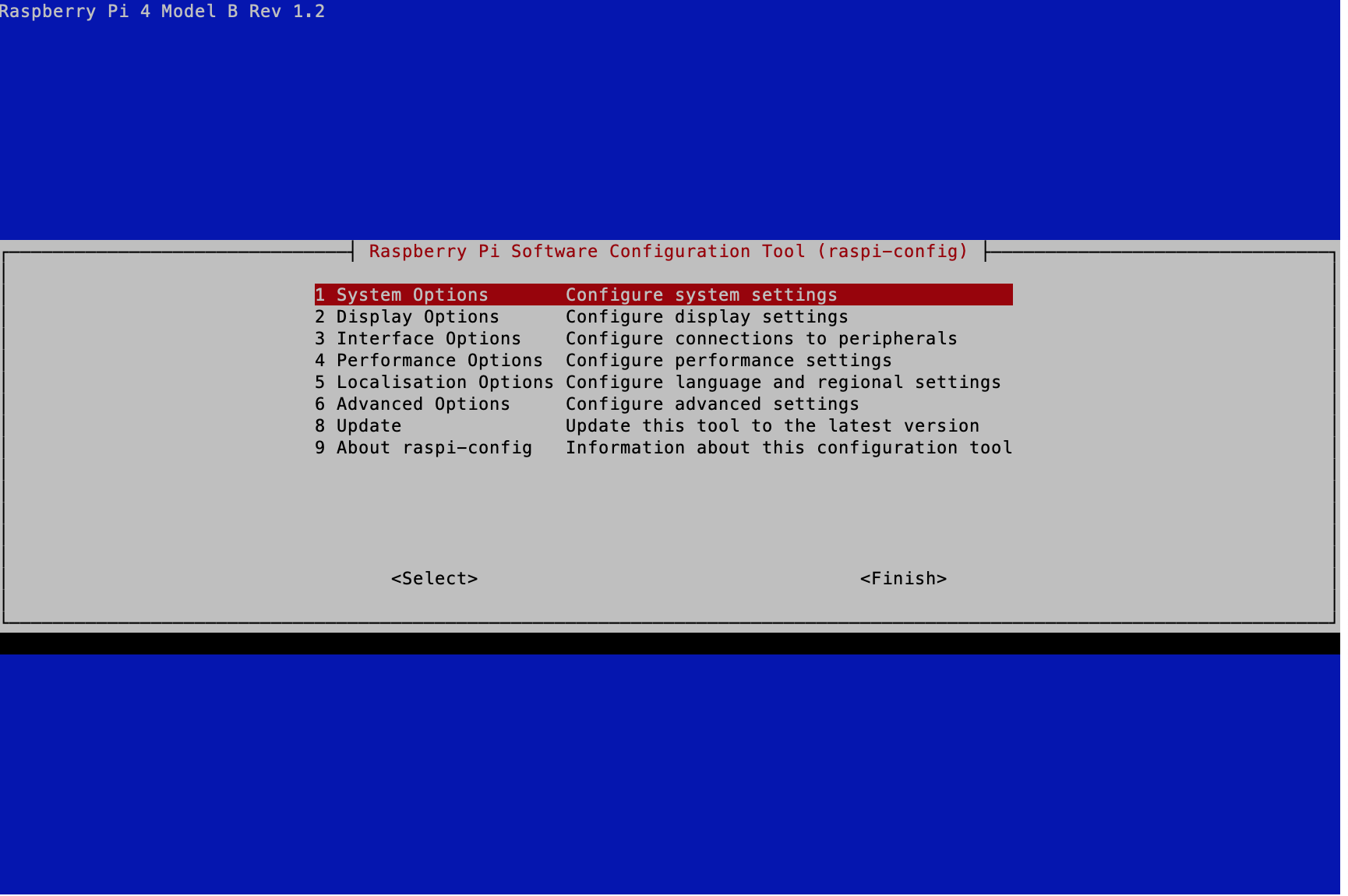
모든 라즈베리파이의 이름을 변경하고 나면 재접속을 할때 접속 주소가 달라집니다. 마스터(master)의 경우 ssh pi@master.local이 되고 이름을 변경한 첫 번째 워커(worker1)의 경우 접속 주소는 ssh pi@worker1.local, 이름을 두 번째 워커(worker2)로 변경한 경우 접속 주소 ssh pi@worker2.local 가 됩니다. 재접속을 하면 이름이 바뀐 것을 확인하실 수 있습니다.
재접속을 할때 keygen을 다시 쳐야할 수도 있습니다. 그럴 때는 ssh-keygen -R master.local 처럼 기존의 코드에서 바뀐이름으로 쳐주면 다시 접속할 수 있습니다.
아래의 코드는 자신이 가진 모든 라즈베리파이에서 실행하는 코드입니다.
모든 라즈베리파이의 업데이트와 업그레이드가 끝나면 라즈베리파이에 java와 에디터 vim을 설치해줍니다. java 설치에는 시간이 좀 소요됩니다.
1
2
3
|
sudo apt-get install vim -y
sudo apt install openjdk-8-jdk openjdk-8-jre -y
|
이제 모든 라즈베리파이에서 hosts 파일을 변경해줍니다. hosts의 내용은 각 파이의 명칭과 ip를 적어줍니다. ip는 각 파이에서 ifconfig로 확인할 수 있습니다.
아래의 코드는 자신이 가진 모든 라즈베리파이에서 실행하는 코드입니다.
1
2
3
|
ifconfig
sudo vim /etc/hosts
|
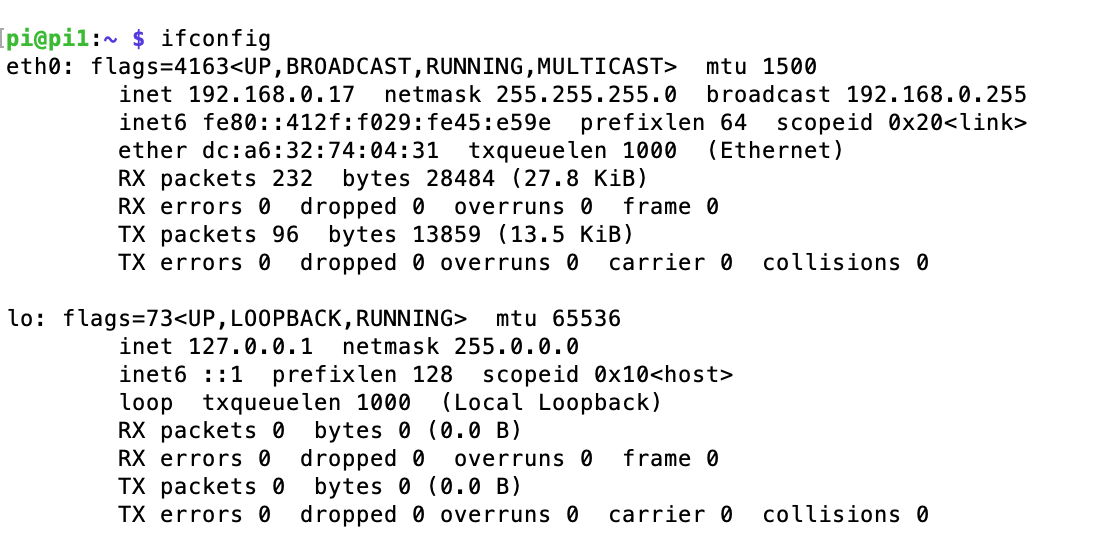
위 사진에서 inet 부분이 자신의 ip가 됩니다. 이 과정을 모든 라즈베리파이에서 진행하여 각 라즈베리파이의 ip 번호를 알아냅니다.
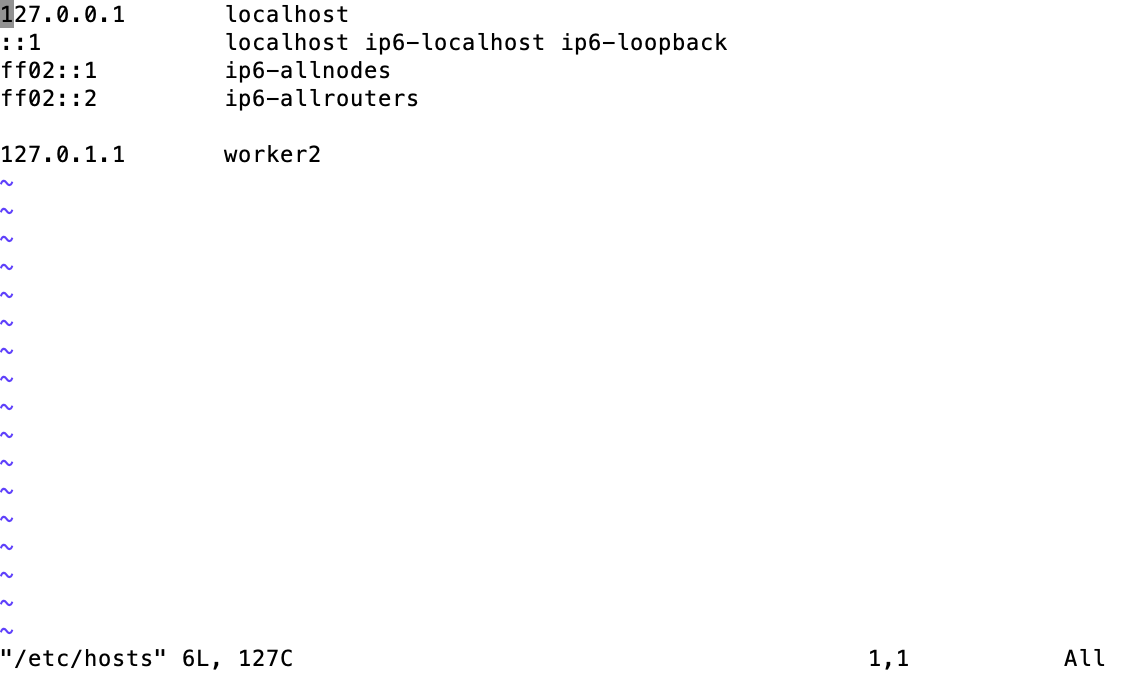
vim을 통해 파일에 들어가면 위와 같은 모습이 보입니다. 이제 i를 눌러 줍니다. 그러면 insert 모드로 바뀌게 되며 내용을 변경하거나 입력할 수 있습니다. hosts 파일의 위의 4줄은 변경하지 말고 그 밑에 값을 아래와 같이 자신의 라즈베리파이들의 ip와 이름으로 변경해줍니다. 변경이 완료되면 esc를 누르고, :w, :q를 누르면 변경사항이 저장되고 vim에서 나가집니다.
1
2
3
|
192.168.0.17 master
192.168.0.15 worker1
192.168.0.14 worker2
|
아래의 코드는 마스터 라즈베리파이에서 실행하는 코드입니다.
이제 마스터 라즈베리파이에서 권한을 설정할 디렉토리를 만들어줍니다.
이제 마스터로 사용할 라즈베리파이에서 설정을 만들어줍니다. 설정파일에는 아래와 같이 각 라즈베리파이의 명칭과 ip를 적은 정보를 입력합니다.
1
2
3
4
|
cd ~/.ssh
touch config
vim config
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#config 파일 내용
Host master
User pi
Hostname 192.168.0.17
Host worker1
User pi
Hostname 192.168.0.15
Host worker2
User pi
Hostname 192.168.0.14
|
아래의 코드는 모든 라즈베리파이에서 실행하는 코드입니다.
이제 모든 라즈베리파이에서 키값을 만들어줍니다. 아래의 코드들 치면 문구가 뜨는데 그냥 엔터를 여러번 눌러주시면 됩니다.
아래의 코드는 워커 라즈베리파이들에서만 실행하는 코드입니다.
마스터를 제외한 라즈베리파이에서 아래의 명령어를 쳐 마스터의 권한 부여합니다. 이 명령어를 치면 마스터에 연결하겠습니까 라는 문구가 나오는데 yes를 타이핑 해주면 됩니다. 입력이 완료되면 마스터 라즈베리파이의 비밀번호를 입력해주어야 하는데 비밀번호 변경을 하지 않았으니 raspberry를 입력해주시면 됩니다.
1
|
cat ~/.ssh/id_ed25519.pub | ssh pi@master 'cat >> .ssh/authorized_keys'
|
아래의 코드는 마스터 라즈베리파이에서 실행하는 코드입니다.
다시 마스터 라즈베리파이로 돌아와 마스터의 키에 권한을 부여합니다.
1
2
|
cd
cat .ssh/id_ed25519.pub >> .ssh/authorized_keys
|
모든 라즈베리파이 수 만큼 아래의 명령어를 입력합니다. 저는 총 2개의 워커를 사용하기 때문에 worker1, worker2에 대해 입력하겠습니다. 입력하면 yes 타이핑과 비밀번호를 입력하게 됩니다.
1
2
3
4
|
scp ~/.ssh/authorized_keys worker1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys worker2:~/.ssh/authorized_keys
scp ~/.ssh/config worker1:~/.ssh/config
scp ~/.ssh/config worker2:~/.ssh/config
|
- 서로 연동을 하면 마스터의 라즈베리파이에서 각 워커들에 접속할 수 있습니다.
마스터에서 다른 라즈베리파이(워커) 조작하기
마스터에서 워커 라즈베리파이를 조작할 수 있게 설정파일에 함수를 입력해줍니다.
아래의 코드는 마스터 라즈베리파이에서 실행하는 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#bashrc 파일 내용
function otherpis {
grep "worker" /etc/hosts | awk '{print $2}' | grep -v $(hostname)
}
function clustercmd {
for pi in $(otherpis); do ssh $pi "$@"; done
$@
}
function clusterreboot {
clustercmd sudo shutdown -r now
}
function clustershutdown {
clustercmd sudo shutdown now
}
function clusterscp {
for pi in $(otherpis); do
cat $1 | ssh $pi "sudo tee $1" > /dev/null 2>&1
done
}
|
변경된 설정내용을 다른 모든 파이에 적용해줍니다. 마스터 라즈베리파이에서 아래의 명령어로 입력하면 다른 모든 파이에 변경된 설정이 적용됩니다.
1
2
3
|
source ~/.bashrc
clusterscp ~/.bashrc
clustercmd source ~/.bashrc
|
하둡 설치
하둡은 마스터 라즈베리파이에서 설치한 이후에 워커 라즈베리파이에 설정 및 파일들을 복사해 넘겨주기에 아래의 코드들은 오직 마스터 라즈베리파이에서만 진행하게 됩니다.
아래의 코드들은 마스터 라즈베리파이에서 실행하는 코드입니다.
아래 주소에 따라 하둡을 설치합니다. 하둡의 버전은 3.2.1 버전을 사용해 줍니다. 3.3.0의 경우 java나 나중에 설치할 spark와 연동을 할때 에러가 발생하지 않게 하기 위해 3.2.1 버전을 사용합니다. 하둡의 설치 파일 다운로드와 압축 해제가 끝나면 하둡 폴더에 권한을 부여합니다.
1
2
3
4
5
6
7
|
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
sudo tar -xvf hadoop-3.2.1.tar.gz -C /opt/
rm hadoop-3.2.1.tar.gz && cd /opt
sudo mv hadoop-3.2.1 hadoop
sudo chown pi:pi -R /opt/hadoop
|
하둡 관련 폴더 경로를 설정파일에 지정해줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# bashrc 파일을 열고 맨 처음에 보면 for examples이 보인다 그 밑에 아래의 내용을 입력한다.
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
|
아래 명령어로 적용
하둡 환경설정에도 자바 경로를 입력해준다.
1
|
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
|
1
2
|
# hadoop-env의 내용
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
|
아래 명령어로 마스터 라즈베리파이에 하둡이 잘 설치된지 확인할 수 있다.
1
|
hadoop version | grep Hadoop
|
하둡 싱글 노드 설정 적용하기
아래의 코드들은 마스터 라즈베리파이에서 실행하는 코드입니다.
하둡이 마스터 라즈베리파이에 잘 작동하는지 확인하기 위해 아래 과정을 진행합니다. 만약 싱글 노드 설정이 필요 없으시면 바로 분산시스템 적용하기로 넘어가셔도 무방합니다.
XML 파일이 있는 위치로 디렉토리를 변경해줍니다.
1
|
cd /opt/hadoop/etc/hadoop
|
먼저 core-site.xml, hdfs-site.xml 2개의 파일을 변경해줍니다. 파일 내용을 입력할 때는 <configuration> 아래에 입력해야한다.
1
2
3
4
5
|
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
|
데이터노드와 네임노드를 저장할 공간을 만들어 준다. 그리고 해당 폴더에 권한을 부여한다.
1
2
3
4
|
sudo mkdir -p /opt/hadoop_tmp/hdfs/datanode
sudo mkdir -p /opt/hadoop_tmp/hdfs/namenode
sudo chown pi:pi -R /opt/hadoop_tmp
|
이제 yarn 설정과 관련된 다른 두 개 설정 파일도 변경해준다.
1
2
3
4
|
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
|
1
2
3
4
5
6
7
8
|
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
|
아래의 명령어로 마스터 라즈베리파이에서 하둡 시스템이 잘 작동하는지 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
|
cd
hdfs namenode -format
start-dfs.sh
start-yarn.sh
jps
stop-all.sh
|
jps의 결과가 NameNode, ResourceManager, NodeManager, SecondaryNameNode, Jps, DataNode 이렇게 6개가 있으면 작동이 잘되었다는 것입니다.
하둡 분산 시스템 설정하기
아래의 코드들은 마스터 라즈베리파이에서 실행하는 코드입니다.
다른 모든 라즈베리파이에도 하둡을 설치하기 위해 폴더를 만들고 권한을 설정합니다. 마스터 라즈베리파이에서 clustercmd 명령어를 통해 다른 워커 라즈베리파이를 조작할 수 있습니다.
1
2
3
4
|
clustercmd sudo mkdir -p /opt/hadoop_tmp/hdfs
clustercmd sudo chown pi:pi –R /opt/hadoop_tmp
clustercmd sudo mkdir -p /opt/hadoop
clustercmd sudo chown pi:pi /opt/hadoop
|
먼저 설정 파일이 있는 디렉토리로 변경해줍니다.
1
|
cd /opt/hadoop/etc/hadoop
|
이제 앞서 단일 하둡 시스템에서 편집한 4개의 파일을 다시 편집해 줍니다. 마찬가지로 <configuration> 사이에 내용을 입력해줍니다.
1
2
3
4
|
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>\
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.memory-mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.map.resource.memory-mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.reduce.resource.memory-mb</name>
<value>256</value>
</property>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
|
아래 명령어를 통해 다른 라즈베리파이에 하둡 파일과 설정을 복사해줍니다.
1
|
for pi in $(otherpis); do rsync –avxP $HADOOP_HOME $pi:/opt; done
|
설정 파일 변경이 끝나면 다른 라즈베리파이에서 데이터 노드와 네임 노드를 삭제하여 초기화 시켜줍니다. 이후 네임 노드(name node)가 마스터에서 작동하지 않을 수 있기에 초기화 과정을 거쳐줍니다.
1
2
|
clustercmd rm –rf /opt/hadoop_tmp/hdfs/datanode/*
clustercmd rm –rf /opt/hadoop_tmp/hdfs/namenode/*
|
하둡 설정 파일을 저장하는 공간에 마스터와 워커들에 대한 정보를 만들어줍니다.
1
2
3
4
|
cd /opt/hadoop/etc/hadoop
touch master
vim master
|
1
2
3
4
|
# localhost를 지우고 아래 내용을 입력합니다.
worker1
worker2
|
1
2
|
clusterscp ~/.bashrc
clustercmd source ~/.bashrc
|
기존에 실행한 하둡 파일을 멈춰주고 변경된 설정파일의 적용을 위해서 전체 라즈베리파이의 재부팅을 해줍니다.
각 라즈베리파이들을 재시작하고 다시 접속한 이후 마스터 라즈베리파이에서 아래의 명령어를 실행합니다.
1
2
3
|
hdfs namenode -format
start-dfs.sh && start-yarn.sh
jps
|
jps 를 쳤을때 마스터에는 namenode가 있고 워커 라즈베리파이에 jps를 쳤을 때 datanode가 있으면 분산 시스템이 잘 적용된 것입니다.
1
2
|
yarn node –list
hadoop dfsadmin -report
|
위 명령어를 쳐서 자신의 워커 개수만큼의 노드 수가 나오면 분산 시스템이 잘 적용된 것입니다. 이외에도 9870, 8088등의 번호로 hdfs와 yarn 실행 환경을 웹 상에서 확인하실 수 있습니다. 정확한 방법은 master.local:9870, master.local:8088 이며 만약 마스터 이름을 변경했다면 master.local 자리에 자신의 마스터 라즈베리파이의 이름을 적어주어야 합니다.
word count로 하둡 분산 시스템 테스트하기
먼저 하둡 공간에 텍스트 파일을 저장할 장소를 만듭니다.
1
2
3
|
hdfs dfs -mkdir -p /user/pi
hdfs dfs -mkdir books
cd ~
|
텍스트 파일은 아래의 링크에서 받아오실 수 있습니다.
1
2
3
4
5
6
7
|
wget -O alice.txt https://www.gutenberg.org/files/11/11-0.txt
wget -O holmes.txt https://www.gutenberg.org/files/1661/1661-0.txt
wget -O frankenstein.txt https://www.gutenberg.org/files/84/84-0.txt
hdfs dfs -put alice.txt holmes.txt frankenstein.txt books
hdfs dfs -ls books
|
북 디렉토리에 있는 모든 파일에 대해 워드 카운트를 실행하고 output에 저장합니다.
1
|
yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount "books/*" output
|
이제 output에 들어간 워드 카운트 결과를 확인합니다.
1
2
3
|
hdfs dfs -ls output
hdfs dfs -cat output/part-r-00000 | less
|
spark 설치
spark 설치는 오직 마스터 라즈베리파이에서 이루어집니다. 하둡의 분산 시스템 위에 스파크가 올라가는 것이기 때문에 다른 워커 라즈베리파이에 설치할 필요가 없는 것입니다. 스파크 버전의 최신 버전은 3.0.1 이지만 2.4.7을 받아 줍니다. 왜냐하면 최신 스파크 3.0.1 with hadooop3.2 는 자바 가상머신과 충돌이 일어날 수 있기 때문입니다. 또한 외부 접속용 클러스터 매니저인 livy와도 충돌이 일어날 수 있습니다.
아래의 명령어로 스파크를 설치하고 압축을 해제해 줍니다. 압축을 해제한 이후에는 스파크 파일의 내용을 옮겨주고 파일에 권한을 부여해줍니다.
1
2
3
4
5
|
wget https://downloads.apache.org/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz
sudo tar -xvf spark-2.4.7-bin-hadoop2.7.tgz -C /opt/
rm spark-2.4.7-bin-hadoop2.7.tgz && cd /opt
sudo mv spark-2.4.7-bin-hadoop2.7 spark
sudo chown pi:pi -R /opt/spark
|
하둡과 마찬가지로 bashrc 파일에 하둡 설정을 적어준 곳 뒤에 이어서 스파크 설정도 적어줍니다.
1
2
3
|
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
|
변경된 설정을 적용해 주고 설치가 잘되었는지 확인합니다.
1
2
|
source ~/.bashrc
spark-shell --version
|
spark 예제로 작동 확인하기
스파크의 예제는 파이 값(3.14…)을 확인하는 것입니다. 파이 값을 계산하는 예제는 스파크 기본 예제로 있습니다.
1
|
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.7.jar
|
얀 클러스터 모드로 작동한 예제의 결괏값은 하둡 웹 UI에서 찾아볼 수 있습니다. “master.local:8088” 주소로 들어가면 아래와 같은 화면이 보입니다 이 화면에서 애플리케이션 id를 눌러줍니다.

그 다음에 밑으로 내려 보면 아래 화면이 보입니다. 이 화면에서 logs를 클릭한 다음 주소에 worker2 다음에 .local을 붙이면 접속할 수 있습니다.

주소에 .local을 붙이고 접속하면 아래와 같은 화면이 보입니다. 이 화면에서 맨 마지막 줄에 있는 “stdout : Total file length is 33 bytes.“를 클릭합니다.

그러면 최종적으로 아래 화면과 같이 파이(3.14 …)값을 확인할 수 있습니다.
